通过网站XML采集网站所有文章
情景
因为本站主服务器每日晚上都会断电,所以需要将本站的静态HTML上传到备用服务器上,所以就需要将网站所有的文章以及首页都保存成html文件。
我用AI写的一个python,经过测试OK。
代码分析
这段代码是一个Python程序,用于从XML sitemap中获取链接,下载HTML页面和相关资源,并检查文件是否需要更新。主要功能如下:
-
导入所需库:包括
hashlib、logging、os、re、requests、urllib.parse、BeautifulSoup和Tag。 -
设置日志记录:使用
logging库配置基础日志记录级别和格式。 -
定义辅助函数:
is_xml_link: 判断URL是否为XML文件。safe_download_resource: 安全地下载资源文件,支持重试和超时。process_html: 解析HTML内容,下载并修改资源链接。check_for_updates_and_download: 检查文件是否需要更新,如有则下载。download_and_save_html_with_resources_updated: 下载HTML及其资源,支持XML文件,附带更新检查。extract_links_from_xml: 递归地从XML sitemap中提取链接。load_collected_links: 从JSON文件加载已采集的链接。
-
主函数
main:- 加载已采集链接的JSON文件。
- 将首页
https://wnluo.com添加到已采集链接集合中。 - 从XML sitemap中提取所有链接。
- 添加主页链接到链接列表。
- 遍历链接列表,首先检查是否为首页,如果是,则下载。然后检查链接是否已经采集,如果未采集,再下载HTML页面和资源。将新采集的链接添加到集合中。
- 保存更新的已采集链接到JSON文件。
这个程序首先从指定的XML sitemap开始,递归地获取所有链接,并检查这些链接的文件是否需要更新。对于HTML页面,它还会下载页面中引用的所有资源(如图片、CSS和JavaScript文件)。所有已采集的链接存储在一个JSON文件中,以便下次运行时使用。现在,首页https://wnluo.com会始终在程序运行时下载,即使之前已经存在于JSON文件中。
代码
请自行将https://wnluo.com 更换为您的域名。
import hashlib
import logging
import os
import re
import requests
import urllib.parse
from bs4 import BeautifulSoup, Tag
from requests.exceptions import RequestException
import json
# 设置日志记录配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def is_xml_link(url):
"""判断是否为XML链接"""
return url.endswith(('.xml', '.xml.gz'))
def safe_download_resource(resource_url, local_path, session, timeout=10):
"""下载资源文件到本地路径,支持重试,并设置了超时时间"""
for attempt in range(3):
try:
response = session.get(resource_url, stream=True, timeout=timeout)
if response.status_code == 200:
os.makedirs(os.path.dirname(local_path), exist_ok=True)
with open(local_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
logging.info(f"Downloaded {resource_url} to {local_path}")
break
else:
logging.info(f"Failed to download {resource_url}, status code: {response.status_code}")
except RequestException as e:
if attempt < 2:
logging.info(f"Download error occurred, retrying {attempt + 1}/3: {e}")
continue
else:
logging.info(f"Failed to download after retries: {e}")
return False
return True
def process_html(html_content, base_url, output_folder, session):
"""处理HTML内容,下载并重写资源链接"""
soup = BeautifulSoup(html_content, 'html.parser')
resource_types = ['.jpg', '.png', '.webp', '.gif', '.svg', '.css', '.js']
for tag in soup.find_all(['img', 'link', 'script']):
if tag.name == 'img':
attr_name = 'src'
elif tag.name == 'link' and tag.get('rel') == ['stylesheet']:
attr_name = 'href'
elif tag.name == 'script':
attr_name = 'src'
else:
continue
src = tag.get(attr_name)
if src and not src.startswith(('http:', 'https:')):
src = urllib.parse.urljoin(base_url, src)
if src and any(src.endswith(ext) for ext in resource_types):
local_path = os.path.join(output_folder, src[len(base_url):])
if not safe_download_resource(src, local_path, session):
logging.info(f"Skipped broken resource: {src}")
else:
if tag.name == 'link' or tag.name == 'script':
tag[attr_name] = os.path.relpath(local_path, output_folder)
else: # img标签
tag['src'] = os.path.relpath(local_path, output_folder)
return str(soup)
def check_for_updates_and_download(link, local_path, session, timeout=10):
"""检查文件是否有更新,如有则下载"""
remote_md5 = None
if os.path.exists(local_path):
with open(local_path, 'rb') as file:
local_md5 = hashlib.md5(file.read()).hexdigest()
else:
local_md5 = None
try:
response = session.head(link, allow_redirects=True, timeout=timeout)
if response.status_code == 200:
remote_etag = response.headers.get('ETag')
if remote_etag: # 使用ETag进行快速条件检查
remote_md5 = remote_etag.strip('"')
else: # 如果没有ETag,则实际下载以计算MD5
response = session.get(link, stream=True, timeout=timeout)
if response.status_code == 200:
remote_md5 = hashlib.md5(response.content).hexdigest()
except Exception as e:
logging.info(f"Error checking updates for {link}: {e}")
return False
if remote_md5 != local_md5:
# 内容有更新,下载文件
if safe_download_resource(link, local_path, session, timeout):
logging.info(f"Updated content downloaded from {link} to {local_path}")
return True
else:
logging.info(f"No update needed, skipping download of {link}")
return False
def download_and_save_html_with_resources_updated(link, output_folder='html_files', filename=None):
"""下载HTML及其资源并保存,带有更新检查,同时支持XML文件下载"""
headers = {'User-Agent': 'WNLUOTESTURL'}
try:
response = requests.get(link, headers=headers)
if response.status_code == 200:
content_type = response.headers.get('Content-Type', '').lower()
if 'text/html' in content_type:
# 处理HTML内容
html_content = response.text
base_url = link.rsplit('/', 1)[0] + '/' # 获取基础URL路径
# 使用Session以复用连接并进行重试
with requests.Session() as session:
processed_html = process_html(html_content, base_url, output_folder, session)
# 保存处理后的HTML前,检查更新
if filename:
save_path = os.path.join(output_folder, filename)
else:
save_path = os.path.join(output_folder, os.path.basename(link))
check_for_updates_and_download(link, save_path, session)
# 强制保存首页
if link == 'https://wnluo.com':
with open(save_path, 'w', encoding='utf-8') as file:
file.write(processed_html)
logging.info(f"Saved {link} as {save_path} with resources")
elif 'application/xml' in content_type or link.endswith(('.xml', '.xml.gz')):
# 处理XML文件下载
if filename:
save_path = os.path.join(output_folder, filename)
else:
# 保持路径一致,去除base_url部分
relative_path = link.replace(base_url, '', 1) if link.startswith(base_url) else link.split('/')[-1]
save_path = os.path.join(output_folder, relative_path)
# 下载XML文件
if check_for_updates_and_download(link, save_path, session):
logging.info(f"XML file downloaded from {link} to {save_path}")
else:
logging.warning(f"Unsupported content type for {link}: {content_type}")
except Exception as e:
logging.error(f"Error downloading {link} or processing resources: {e}")
def extract_links_from_xml(xml_url, depth=0, max_depth=5, collected_links=None):
links = [] # 初始化links列表
headers = {'User-Agent': 'WNLUOTESTURL'}
if depth > max_depth:
print("Reached maximum recursion depth, stopping.")
return []
if collected_links is None:
collected_links = set()
try:
response = requests.get(xml_url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'xml')
for link in soup.find_all(['loc']):
href = link.text
if is_xml_link(href) and href not in collected_links:
collected_links.add(href)
links.extend(extract_links_from_xml(href, depth + 1, max_depth, collected_links))
elif href.endswith(('.html', '.htm')) and href not in collected_links:
collected_links.add(href)
links.append(href)
return links
else:
print(f"Failed to fetch XML at {xml_url}, status code: {response.status_code}")
except Exception as e:
print(f"Error fetching XML: {e}")
return links
def load_collected_links(file_path):
collected_links = set()
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
collected_links.update(json.load(file))
return collected_links
def main():
collected_links_file = 'collected_links.json'
# 加载已采集链接
collected_links = load_collected_links(collected_links_file)
collected_links.add('https://wnluo.com') # 添加首页到已采集链接
start_xml_url = 'https://wnluo.com/sitemap.xml'
all_links = extract_links_from_xml(start_xml_url)
home_page_url = 'https://wnluo.com'
all_links.append((home_page_url, 'index.html'))
for link in all_links:
if isinstance(link, tuple):
link_url, filename = link
else:
link_url, filename = link, None
# 检查链接是否已采集,但首页除外
if link_url == home_page_url:
download_and_save_html_with_resources_updated(link_url, output_folder='html_files', filename=filename)
continue
if link_url in collected_links:
continue
if link_url.endswith(('.html', '.htm')):
download_and_save_html_with_resources_updated(link_url, output_folder='html_files', filename=filename)
collected_links.add(link_url)
# 保存更新的已采集链接
with open(collected_links_file, 'w', encoding='utf-8') as file:
json.dump(list(collected_links), file, ensure_ascii=False, indent=2)
if __name__ == "__main__":
main()
测试截图
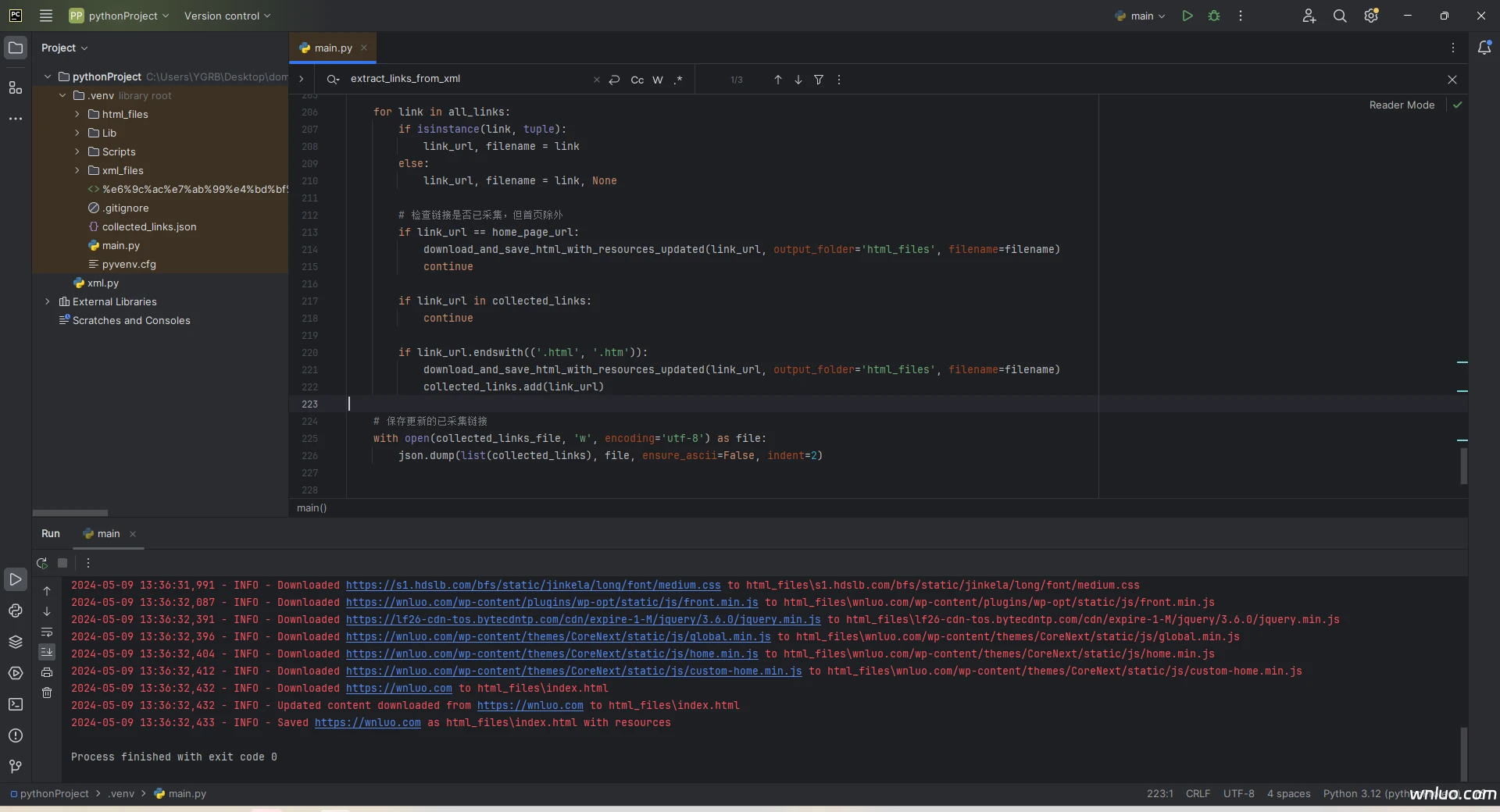
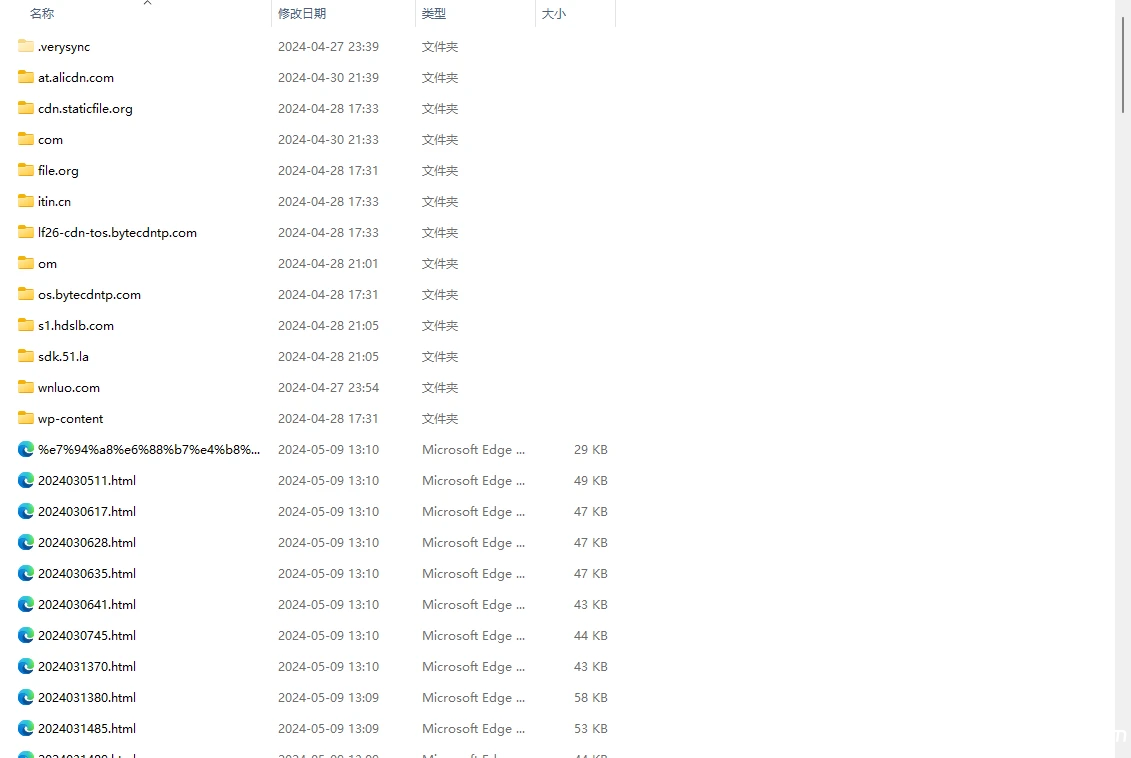
阅读剩余
THE END
